ChindaMT คืออะไร#
ChindaMT เป็นโมเดลแปลไทย-อังกฤษแบบ open-weight ที่ออกแบบมาให้ “เชื่อฟัง” กฎที่คุณใส่ใน prompt ไม่ใช่แค่แปลให้ลื่นแล้วจบ แต่เคารพคำสั่งย่อย ๆ ที่ผู้ใช้กำหนดมาด้วย เช่น ต้องใช้ศัพท์เฉพาะตัวไหน รูปแบบคำตอบเป็นอย่างไร จำกัดความยาวเท่าไหร่ หรือใช้ภาษาทางการขนาดไหน
โมเดลแปลทั่ว ๆ ไปทำได้แค่ส่งคำแปลที่ลื่นไหลออกมา แต่งานแปลในชีวิตจริง ทั้งงานเอกสาร UI string คำแปลในระบบ มักจะมาพร้อมเงื่อนไขชุดหนึ่งเสมอ และนั่นคือช่องว่างที่ ChindaMT พยายามอุด
ผลที่ได้#
ChindaMT-4B เอาชนะ baseline แบบเปิดทั้ง 3 ตัวที่เรานำมาเทียบ ทั้งในการแปลธรรมดาและการแปลตามกฎ
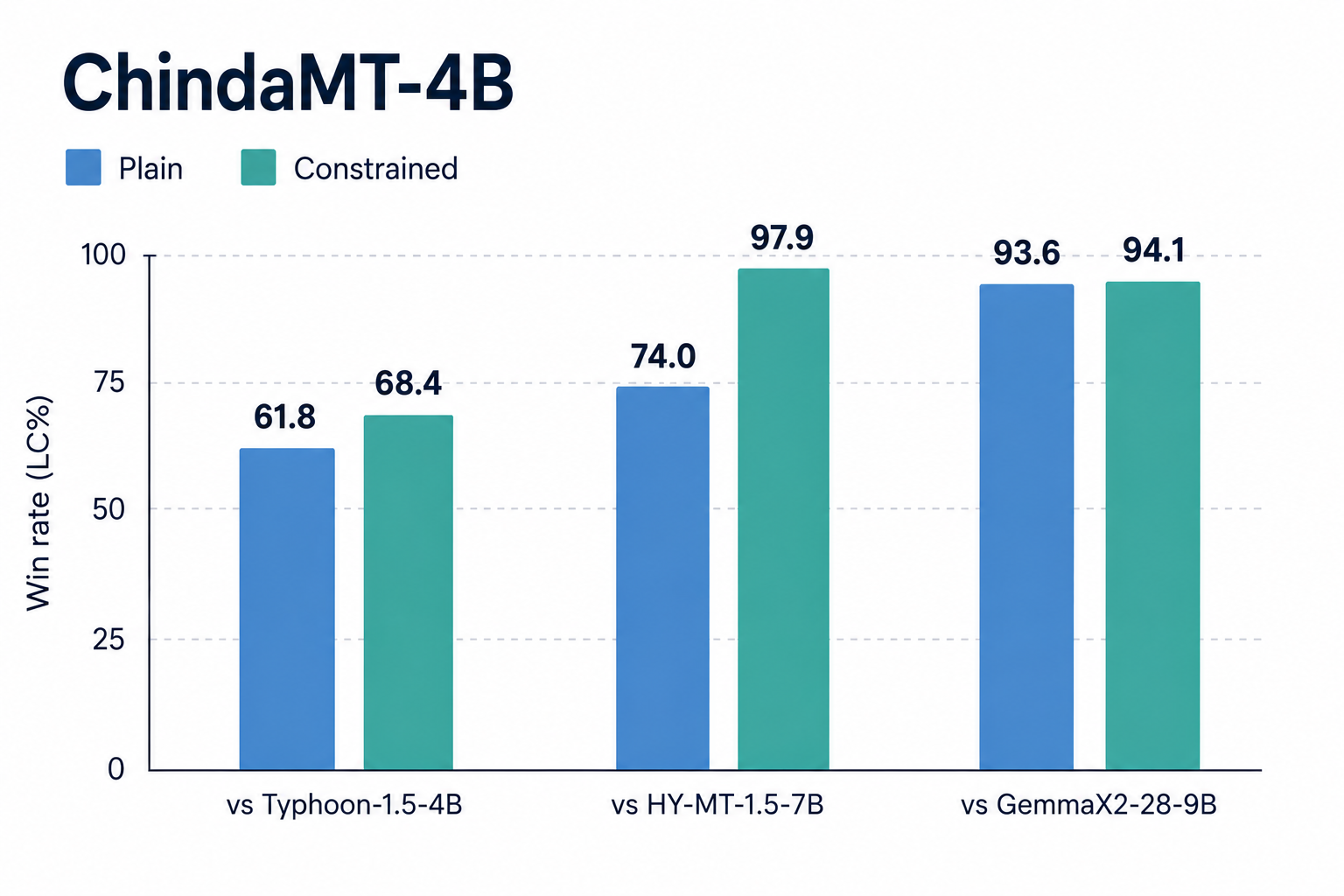
แท่งกราฟแสดงค่าที่เรียกว่า length-controlled win rate (LC%) ค่ายิ่งสูง หมายความว่า ChindaMT ถูกเลือกบ่อยกว่าโดย LLM ที่ทำหน้าที่เป็นกรรมการ โดยปรับ bias ที่กรรมการมักจะชอบคำตอบยาว ๆ ออกไปแล้ว
แท่งสองสีคือสองวิธีถาม:
- Plain คือขอแปลแบบธรรมดา “แปลย่อหน้านี้เป็นภาษาไทย” ไม่มีกฎอะไรเพิ่ม วัดคุณภาพการแปลล้วน ๆ
- Constrained คือใช้ source เดิม แต่ใส่กฎ 1 ถึง 5 ข้อต่อท้าย เช่น “แปลย่อหน้านี้เป็นภาษาไทย ใช้ภาษาทางการ คงตัวเลขให้ครบทุกตัว ตอบเฉพาะคำแปล ห้ามมีคำนำ” คำแปลต้องผ่านทุกข้อ
ChindaMT ได้เปรียบมากที่สุดในฝั่ง Constrained ซึ่งก็คือกรณีที่เกิดขึ้นในงานจริงเกือบทุกครั้ง แต่กลับเป็นจุดที่โมเดลแปลส่วนใหญ่มองข้าม
ดีกว่า base model ที่ใช้ฝึก#
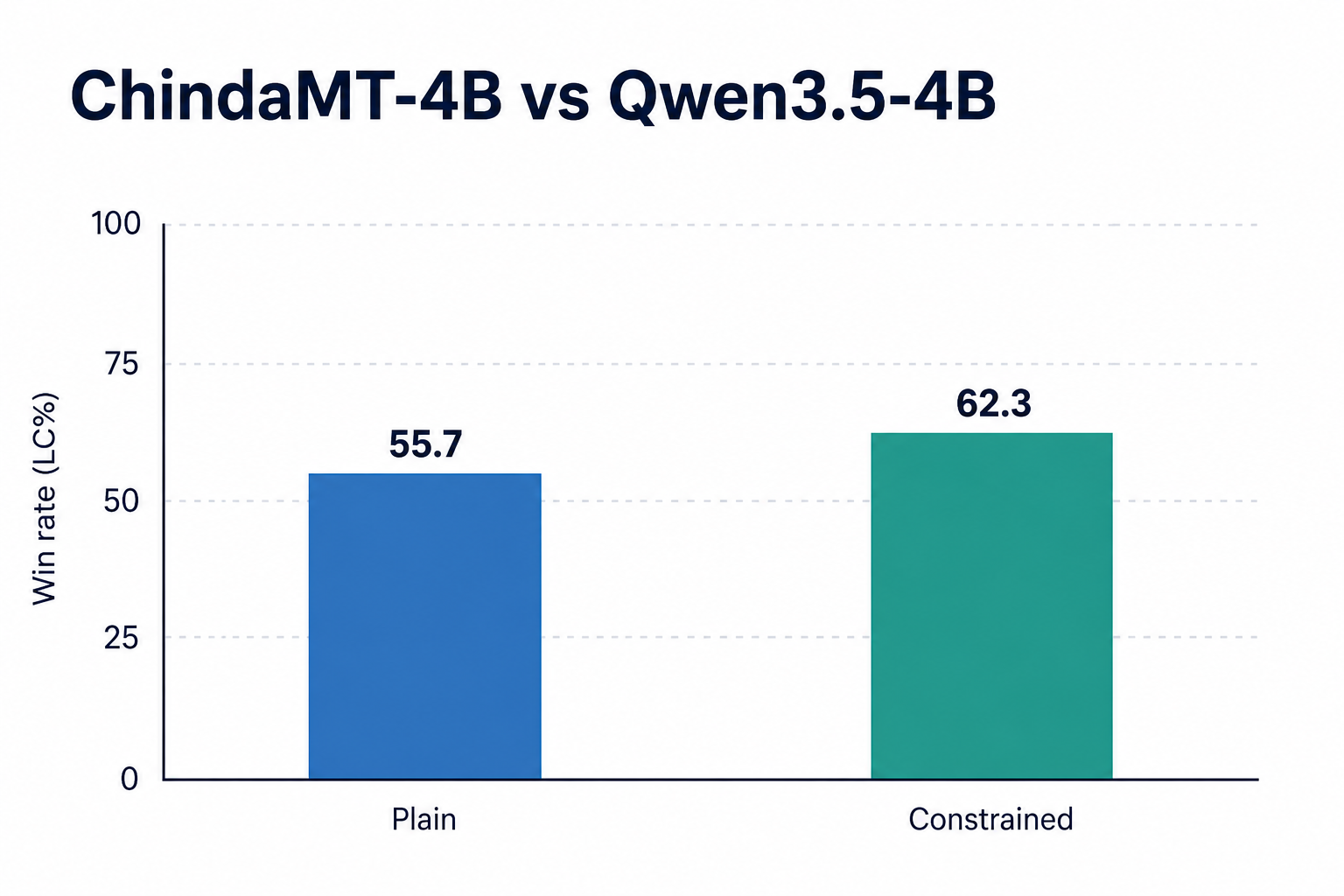
ChindaMT-4B ถูกฝึกต่อยอดจาก Qwen3.5-4B ซึ่งเป็น LLM แบบ open-weight ที่แข็งพอตัวอยู่แล้ว เมื่อนำมาเทียบกันบนชุดทดสอบเดียวกัน ChindaMT-4B ชนะที่ 55.7% LC สำหรับการแปลธรรมดา และ 62.3% LC สำหรับการแปลตามกฎ ทั้งสองแท่งสูงกว่าเส้น 50% ที่เป็นจุดเสมอ ยืนยันได้ว่ากระบวนการฝึกของเราเพิ่มความสามารถในการแปลจริง ไม่ใช่แค่เอาโมเดลใหญ่กว่ามาเทียบ การปรับปรุงทั้งหมดมาจากวิธีเตรียม training data
วิธีการโดยย่อ#
ความได้เปรียบของ ChindaMT ไม่ได้อยู่ที่ model architecture ที่หรูหราอะไร แต่อยู่ที่ วิธีเตรียม training data
ความสามารถที่เราเล็งคือ การแปลแบบทำตามคำสั่ง (instruction-following translation) โมเดลไม่ได้แค่เรียนแปล แต่เรียน “ทำตามกฎใน prompt” ไปพร้อมกัน เรื่องที่น่าสนใจคือ โมเดลที่ฝึกแบบนี้ แปลแบบธรรมดาก็ยังดีกว่าโมเดลแปลธรรมดาด้วยซ้ำ การฝึกให้ทำตามกฎไม่ได้แลกมาด้วยคุณภาพการแปลที่ลดลง แต่กลับทำให้คมขึ้น คุณได้ทั้งสองอย่างในตัวเดียว
สูตรของเราในประโยคเดียว: แทนที่จะ “สุ่มสร้าง” กฎขึ้นมาแล้วลุ้นว่าโมเดลจะทำตามได้ไหม เรามองหาคำแปลไทย-อังกฤษจริง ๆ ที่ทำตามกฎอยู่แล้วโดยธรรมชาติ แล้วให้โมเดลเรียนกฎจากตรงนั้น ทุกกฎที่โมเดลถูกขอให้ทำตามตอนเทรน คือกฎที่นักแปลจริง ๆ เคยทำตามมาก่อนแล้ว
วิธีที่อยู่เบื้องหลังสูตรนี้ และชื่อที่เราใช้เรียกมัน จะเปิดเผยในภายหลัง
เราวัดยังไง#
ทุกการเปรียบเทียบในกราฟด้านบน คือการเทียบแบบ head-to-head pairwise บน test set ที่แยกออกมา ไม่ปนกับ training:
- 400 prompt คู่ แบ่งครึ่งระหว่าง อังกฤษ→ไทย กับ ไทย→อังกฤษ
- 5 โดเมนที่ใช้งานจริง: เอกสารราชการ การเงิน เทคโนโลยี ข้อความ UI ทั่ว ๆ ไป
- prompt แต่ละชุดมาในสองรูปแบบ: Plain (แปลธรรมดา) กับ Constrained (เพิ่มกฎ 1 ถึง 5 ข้อ)
- ใช้ LLM ขนาด 35B แบบเปิด อ่านคำแปลทั้งสองฝั่งแล้วเลือกตัวที่ดีกว่า ลำดับเกณฑ์: ความถูกต้องมาก่อน ตามด้วยการทำตามกฎ จบที่ความลื่นไหลของภาษา
- judge ตัวนี้มีนิสัยชอบคำตอบยาว เราหักออกด้วย length-controlled win rate (LC%) ตามวิธี AlpacaEval v2
- ผลของรุ่น 4B ผ่านการเช็คซ้ำอีก 3 ทาง คือ ตัววัดคุณภาพแบบอ้างอิงสามตัว (CometKiwi, GEMBA-DA, GEMBA-MQM), judge จาก family อื่นที่ไม่ใช่ open-weight, และผู้ประเมินที่เป็นเจ้าของภาษาไทยจริง
ลองได้แล้ววันนี้#
ChindaMT-4B เป็น open weights ภายใต้ Apache-2.0
evaluation suite จะตามมาเร็ว ๆ นี้