What it is#
ChindaMT is an open-weight Thai-English translation model that follows the rules in your prompt: terminology, format, length, register. Most translators just produce a fluent target. ChindaMT respects the rules you put around it.
The result#
ChindaMT-4B wins head-to-head against three open Thai-English baselines.
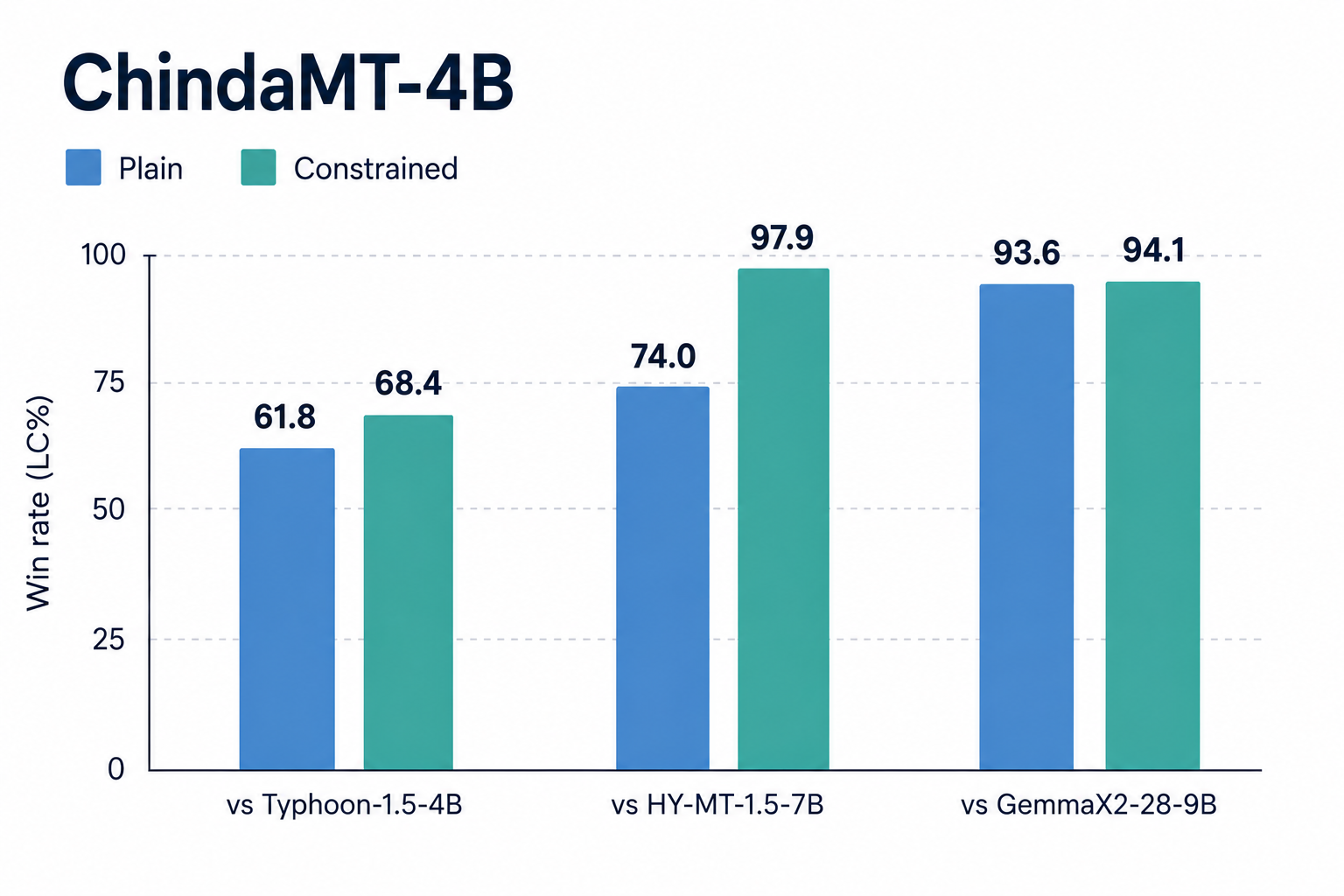
The bars show length-controlled win rate (LC%). A higher value means ChindaMT is preferred more often by an LLM judge that has been corrected for the well-known length bias.
The two bar colors are two ways of asking the model to translate:
- Plain is a normal translation request: “Translate this paragraph into Thai.” No extra constraints. This measures raw translation quality.
- Constrained is the same source extended with one to five explicit rules: “Translate this paragraph into Thai. Use formal Thai. Keep all numbers exactly. Return only the translation, no preface.” The translation has to obey every rule. This measures how well the model handles the prompts you’d actually use in production.
The lift is largest on Constrained, where rule compliance matters, which is the case most translators ignore.
Better than the base model it was built from#
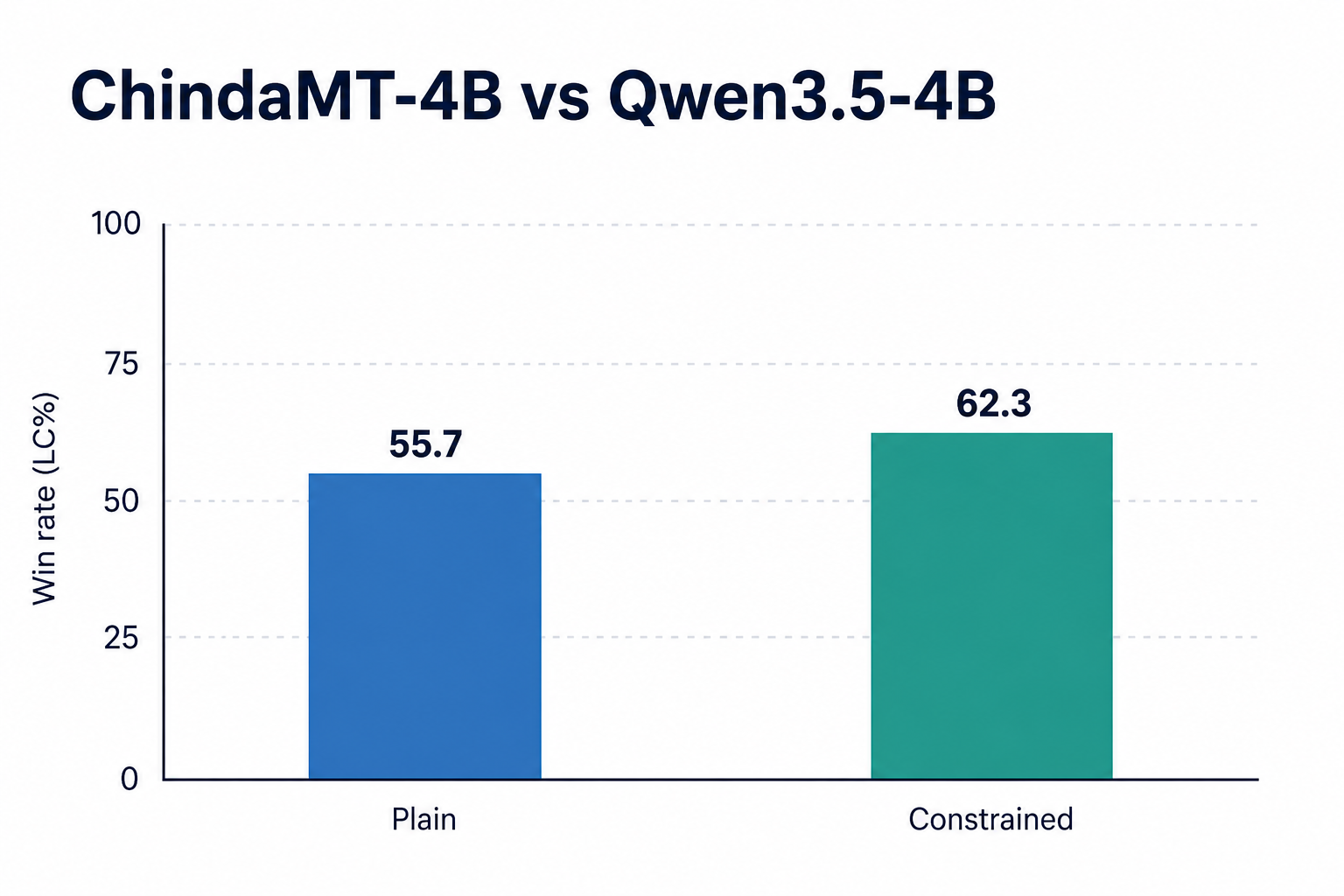
ChindaMT-4B was fine-tuned from Qwen3.5-4B, a strong open-weight LLM. Compared head-to-head on the same test set, ChindaMT-4B wins 55.7% LC on plain translation and 62.3% LC on rule-following translation. Both bars sit above the 50% tie line, confirming that the recipe adds real translation skill on top of an already-capable base. The lift comes entirely from how we prepared the training data, not from a larger model.
Method in brief#
ChindaMT’s edge isn’t a fancier model architecture. It’s how we prepare the training data.
The capability we target is instruction-following translation: the model learns to translate and to respect rules in the prompt at the same time. The counterintuitive part is that a model trained this way can be better than a plain translator even when no rules are given: the same training that teaches it to follow rules also makes its plain translation sharper. You don’t pay a quality tax for the rule-following ability; you get both.
The recipe in one sentence: instead of inventing rules and hoping a model can follow them, we look at real Thai-English translations that already follow rules naturally, and let the model learn the rules from there. Every rule the model is asked to follow during training is one a human translator already followed first.
The method behind that recipe, and the name we give it, will be opened later.
How we measure#
Every comparison in the charts is a pairwise head-to-head on a held-out test set:
- 400 paired prompts, evenly split between English→Thai and Thai→English.
- Five deployment-grade domains: government, finance, tech, UI strings, miscellaneous.
- Each prompt appears in two variants: Plain (translate normally) and Constrained (the same source extended with 1 to 5 explicit rules).
- An open 35B LLM reads both translations side by side and picks the better one, scored on accuracy first, then rule compliance, then fluency.
- That judge has a well-documented preference for longer answers; we correct for it with length-controlled win rate (LC%), the protocol from AlpacaEval v2.
- The 4B numbers are cross-checked three more ways: three independent reference-quality metrics (CometKiwi, GEMBA-DA, GEMBA-MQM), a second judge family, and native-Thai human raters.
Today’s release#
ChindaMT-4B. Open weights, Apache-2.0.
The evaluation suite will be released later so anyone can reproduce or extend the comparison.